PDFport®とは
PDF入稿によるアウトソーシングの業務やペーパーレス化による帳票PDFが多くなってきております。
入稿されたPDFに対してページソート、ロット単位でのファイル分割、連番の追加印字、封入封かん用バーコードの追加印字など様々な加工処理が必要とされています。
また、管理テキストの作成、ページの抜き出し、複数PDFファイルの連結や名寄せなども欠かせない処理となっています。
これらの要望に対応するため、ポーラ・メソッドはPDF加工アプリケーション・PDFport® を開発しました。
【お知らせ】※PDFport® -5発売に伴いPDFport® -4は2025年9月末日をもちまして販売終了となりました。上位版のPDFport®-5をご検討ください。
PDFport®-5
- Microsoft® Windows 11 Pro 日本語版で動作します。
- ポーラ・メソッド独自のPDF解読&出力エンジンを使用した高速処理が特徴です。
- GUI上で加工処理の定義をノーコードで設計でき、作成した加工定義をファイルに保存できます。
- GUI上から加工定義を実行する方法以外に、シンプルな実行コンソールアプリケーションおよびホットフォルダ形式で実行させる補助アプリケーションが付属しています。
バージョン5で追加された主な機能
- 加工定義をホットフォルダ形式で自動実行(補助アプリケーション「PortHF」を追加)
- 2次元バーコードの生成速度が約1.3~2倍に向上
- ワード抽出した文字列を加工するツールを追加(抽出した文字列の切り出し、大文字・小文字変換など)
- 背景用PDFへ入力PDFを重ねる専用面付けツールを追加(事前印刷用PDFを重ね合わせる)
- 増幅PDFツールを追加(1冊子分PDFから指定部数分に増加)
- CSVファイルマージツールを追加(PAF情報へCSVファイル内容をマージ)
- 印字ツール系にて印字色の色空間にGrayを追加
- ワード抽出ツール
アンカー表示精度を向上させた、Bモード表示を追加
領域設定画面で表示用PDFファイルの変更に対応
IVS(異体字)の文字列抽出に対応
PDFport®-5の機能と加工定義の例
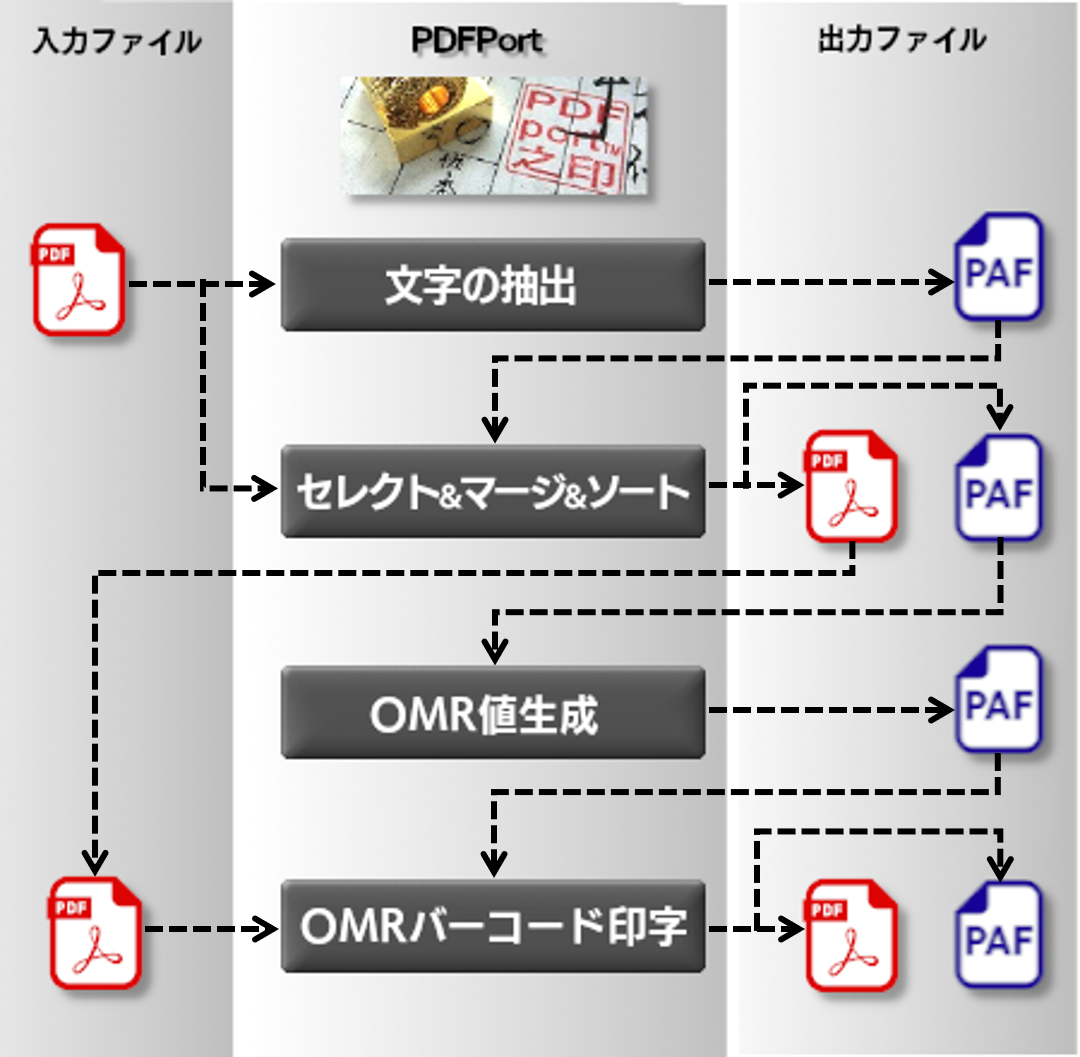
文字列の抽出
入稿されたPDFから1通の始まりページを認識できるユニーク文字や管理番号、ソートに使う文字列などの抽出ができます。
これらはページ属性情報として保持され、テキスト形式で出力もできます(PAFファイル)。
セレクト&マージ&ソート
文字列の抽出で出力されたページ属性(PAFファイル)情報を元にPDFページのソートができます。また、ソート結果に対応したページ属性情報(PAFファイル)の出力もできます。
OMR値生成
ページ属性情報を元に、OMRの値を生成する事ができます。生成した値をPAFファイルで出力もできます。
シート作成・OMR追加印字
ページに余白エリアを作ることができます(ページサイズ変更)。
また、生成されたOMR値をページ上へOMRバーコードとして印字できます。
※PAFファイルとはPDFport独自のページ属性情報ファイルです(Unicode CSV形式のテキストファイル)。
※OMR値はクアディエントジャパン社DS-64i以上に対応しています。
PDFport®-5のツール群を使った加工定義作成画面とツール設定ダイアログ
ツールボックスにリストされている実行ツールを選び、プロセス実行テーブルにセットすることでワークフローを作成します。
各実行ツールには、実行に必要な設定ダイアログを用意しております。
処理実行時には、プロセス実行テーブルに並んだ定義済みツール群が上位から下方に順に実行されPDFは加工されます。
下図のGUIが加工定義の作成および実行画面となります。

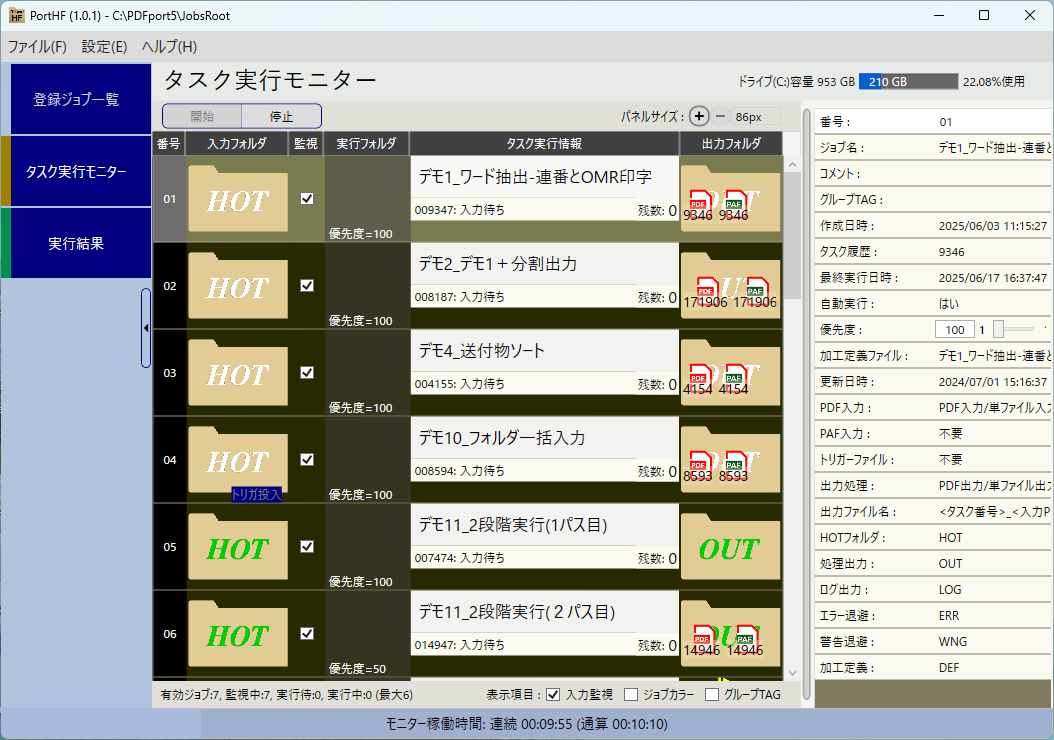
実行補助アプリケーション「PortHF」
作成した加工定義をホットフォルダ形式で実行させる補助アプリケーションです。
加工定義ファイルを最大32個まで登録できます(加工定義1つに対してホットフォルダ1つで管理されます)。
ホットフォルダへPDFファイルをドロップすることで処理されますので、オペレーションが容易になります。※単ファイル入力処理の場合。
※PortHFで利用可能な加工定義は使用できるツール種に制限があります。
PDFport®-5のツール概要

| PDF入力 | |
|---|---|
| 単ファイル入力 | 入力PDFファイルを1つ指定。 |
| フォルダ内PDFの一括入力 | 入力PDFが入ったフォルダーを1つ指定(フォルダ内の全PDFを連結すように読み込みます)。 |
| 増幅PDF入力 | 入力PDFファイルを1つ指定、読み込み直後に指定部数分へ増幅。 |
| PDF出力 | |
| 単ファイル出力 | 処理結果を1つのPDFファイルとして出力。 |
| 分割出力 | 処理結果をファイル分割して出力。 |
| 仕分け出力 (送付ページ数で振分) |
1つの送付物内のページ数の範囲により振り分けてファイル分割出力。 |
| 仕分け出力 (フィールド値で振分) |
ページ属性のフィールド値を参照し、指定ファイル名で振り分けて出力。 |
| ページ索引(ページ属性の生成や加工) | |
| フィールド名の編集 | ページ属性情報にユーザー用フィールドを追加。 |
| ワード抽出 | ページから文字列を抽出。 |
| 顧客番号データ生成 | 顧客番号カウンターを生成。 |
| マクロ定義フィールド | 全体ページ数や1通内ページ数カウンターなどの連番文字列を生成。 |
| 文字列加工 | ワード抽出結果などの文字列に対して文字列加工。 |
| フィールド合成 | フィールドを合成し新しい値のフィールドを生成。 |
| フィールド補完 | 前ページもしくは後ろページ方向へフィールド値を複製し埋める。 |
| バーコード文字列生成 | 特殊なバーコード値を生成。 |
| OMRフィールド生成 | OMRバーコード用のフィールド値を設計。 |
| CSVファイルをマージ | 別途用意したCSVファイルの内容(列)をページ属性へマージ。 |
| PAFファイル出力 | ページ属性情報をPAF形式で保存します(Unicode CSV)。 |
| ページ構成 | |
| ページ挿入 | 指定のページ位置へページを挿入。 |
| ページセレクト | ページ単位での必要なページの指定(ページ抽出)。 |
| ページソート | ページ単位でのページソート設定。 |
| 送付物セレクト | 送付物単位での必要なページの指定(送付物抽出)。 |
| 送付物ソート | 送付物単位でのページソート設定。 |
| レイアウト | |
| PDF貼り付け | 指定PDFをページ上へ貼り付け。 |
| テキスト印字 (TrueTypeフォント) |
MS明朝またはMSゴシックでの印字設定。 |
| テキスト印字 (OCR-Bフォント) |
OCR-Bフォントでの印字設定。 |
| バーコード(日本郵便) | 郵便バーコードでの印字設定。 ※PDFportでバーコード値生成はできません |
| バーコード(ITF) | ITFバーコードでの印字設定。 |
| バーコード(NW-7) | NW-7バーコードでの印字設定。 |
| バーコード(CODE39) | CODE39バーコードでの印字設定。 |
| バーコード(OMR) | OMRバーコードでの印字設定。 |
| 二次元 QR コード | QRでの印字設定。 |
| 二次元 Data Matrix コード | DataMatrixでの印字設定。 |
| シート化 | |
| 背景PDF合成 | 背景PDFを下地シートとし、入力PDFを上に重ねる。 |
| 新規シート作成 | 出力PDFの用紙サイズ等の設定。 |
| 単純面付け(N-Upper) | 単純面付け(N-Upper)設定。 ※ページ属性はリセットされます |
| 串刺し面付け | 串刺し面付け設定。 ※ページ属性はリセットされます |
| 実行制御 | |
| PDFの遂次入力 PDFの遂次出力 |
この2つのツールのセットで使用。 指定フォルダ内のPDFを1ファイルずつ読み込み、ファイル数分の処理を繰り返す。 PDF入力・出力系ツールの代わりに使用。 |
| PDFプレビュー | ワークフロー中にこのツールをセットすると、その加工段階のPDFページを表示 (別のPDF表示アプリを利用して表示)。 |
| 実行時リセット | 出力系ツール直後にこのツールを配置するとそれまでの情報をクリアされ、 このツールの後(下段)から別のPDFを読み込む加工定義を新たに構築できます。 |